Huffman
Coding
What is Huffman Coding?
First of all, let's start with codification in general. When we transmit information, need to convert the data (text, music, video, etc.) into binary code. To do this, we assign a code to each piece of data so we can distinguish them, and decode them later.
If we take a string as an example, for example 'ABACA', we could assign a same-length code to each one of the unique symbols (usually called naive coding).
| Naive Coding | |
| A | 00 |
| B | 01 |
| C | 11 |
Encoded output:
00 01 00 11 0010 char * 8 bits/char = 80 bits
With the obtained table, we could later translate the binary codes back to the text without loosing information on the process, but is this the best way to do this?
Huffman coding improves this process, being a lossless data compression algorithm that assigns variable-length codes based on the frequencies of our input characters.
To determine how to assign the codes to each symbol, we have to take the following steps:
- Analyse the frequency of each character
- Build the binary tree:
- Take the pair of nodes with the least frequency
- Iterate until left with one node
- Starting at the root, label the edge to the left child as 0 and the edge to the right child as 1. Iterate for every child.
- Go over the tree from each leaf to the root, writing down the labeled binary numbers, to generate the code word for each symbol.
A bit of history
The author ofthe paperthat presented the algorithm in 1952 was developed by David Albert Huffman (August 9, 1925 – October 7, 1999), a computer science pioneer from the United States1. The method emerged from a university term paper in an electrical engineering graduate course on information theory, with Robert M. Fano as his professor2.


Huffman did not invent the idea of a coding tree. However, he discovered that assigning the probabilities of the longest codes first and then proceeding along the branches of the tree toward the root, he could arrive at an optimal solution every time. Fano and Shannon had tried to work the problem in the opposite direction, from the root to the leaves, a less efficient solution2.
The optimal code developed by David A. Huffman, and it's variations or improvements "are used in all the mainstream compression formats (e.g., PNG, JPEG, MP3, MPEG, GZIP, and PKZIP)". It's one of the fundamental and most used ideas in data communication, and is still as relevant today as it was before3.
Note: as a curiosity, David A. Huffman was also a pioneer inmathematical origami.The decorations of this page are inspired by the diagrams of his models4.
Beyond Huffman Coding
There aremany variationseach one with it's own particularities. An interesting approach, beautifully explained inBen Tanen's site, is Adaptive Huffman Coding. It consists in calculating the probabilities of the symbols dynamically, updating the tree structure. This way there's no need to pre-process the input, but the method is not widely used in practice, since the cost of updating the tree makes is slower than optimized adaptive arithmetic coding, more flexible and with better compression.
An important limitation of Huffman coding is that with every encoded symbol, up to 1 bit of redundant data can be introduced. With small alphabets, it can make that the length of the original representation doesn't change. Arithmetic Coding tries to avoid this issue5.

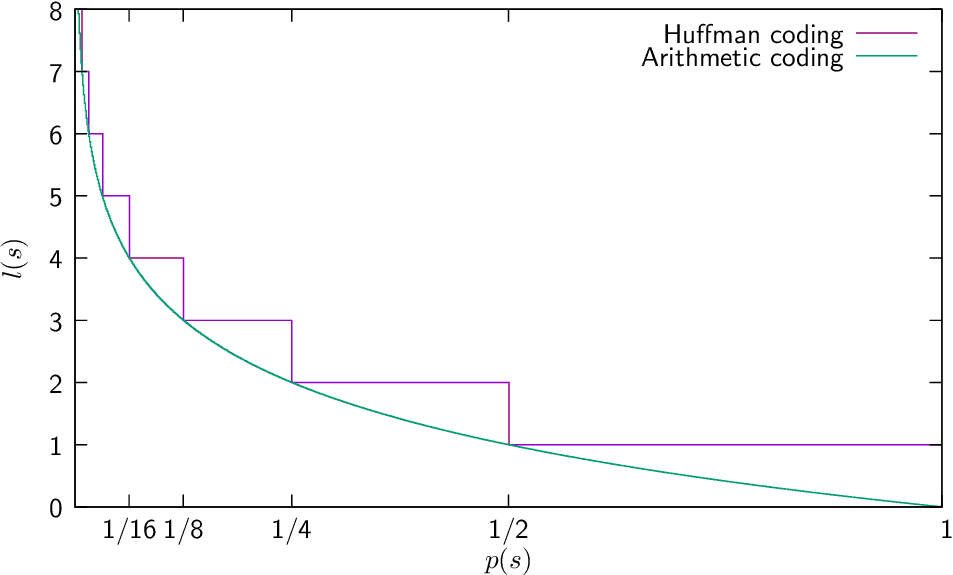
Arithmetic Coding is another form of entropy encoding for lossless data compression. Unlike Huffman, instead of separating the input into component symbols and replacing each with a code, it encodes the entire message into a single number, an arbitrary-precision fraction q, where 0.0 ≤ q < 1.0.
This makes it work better than Huffman for sequencies with very low Entropy.
If you are interested in compression and information theory, it is highly encouraged to learn about it.